


资源编号
617最后更新
2025-03-31
摘要 :
SD绘画原理:stable diffusion生成图片的最简单原理:是从噪声图逐步去噪,最终形成结果,获得想要的效果图片; 我们了解Stable Diffusion 文生图这些原理后,你在使用 S……
SD绘画原理:stable diffusion生成图片的最简单原理:是从噪声图逐步去噪,最终形成结果,获得想要的效果图片;
我们了解Stable Diffusion 文生图这些原理后,你在使用 Stable Diffusion 进行文生图创作时,能更好地调整参数、理解生成结果。
Stable Diffusion 文生图主要依赖于文本编码器、UNet 和变分自编码器(VAE)等核心组件协同工作,将用户输入的文本描述转化为对应的图像。
文本生成图像(Text-to-Image)原理
文生图原理:完全基于噪声生成:初始状态为高斯白噪声x_T ~ N(0, I),扩散模型的核心机制是从纯噪声逐步重构图像,没有初始噪声就无法启动去噪过程。
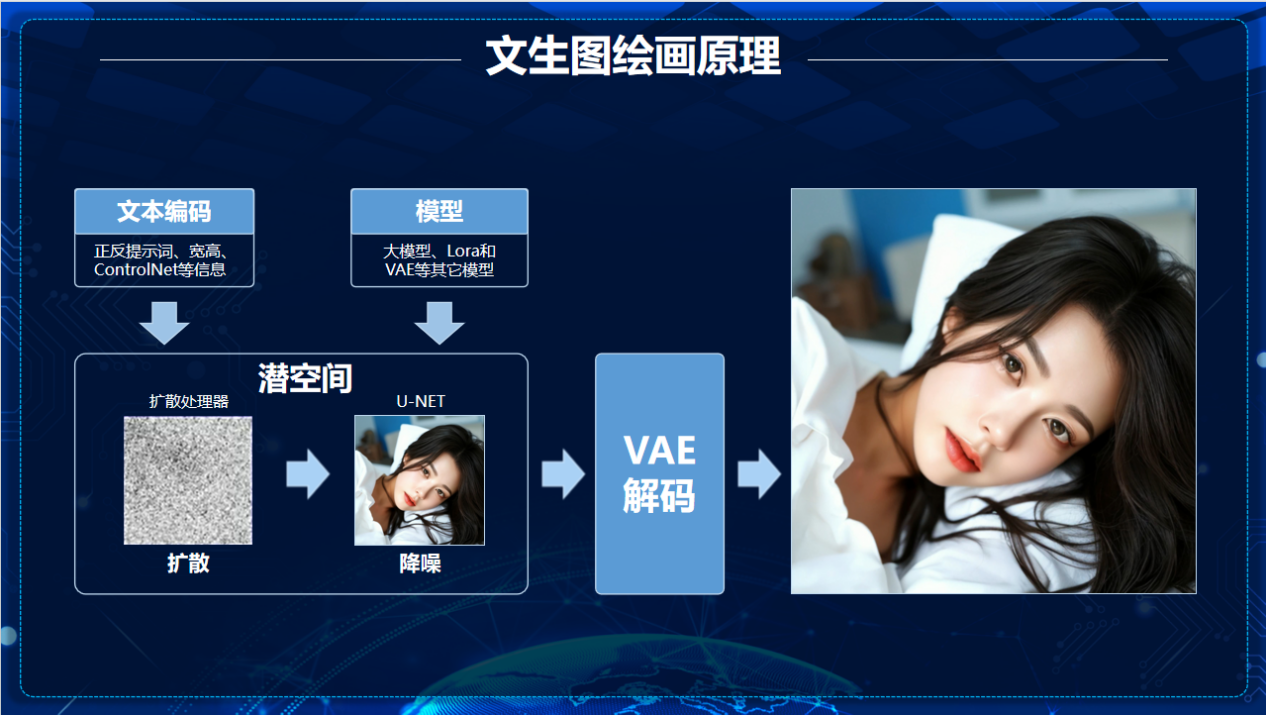
- 核心架构
基于Latent Diffusion Model(潜在扩散模型),通过以下组件协同工作:
- CLIP Text Encoder:将文本提示(Prompt)编码为768维语义向量
- VAE(变分自编码器):负责图像空间(像素空间)与潜在空间(latent space)的相互转换
- UNet:执行扩散过程的核心神经网络,负责在潜在空间中迭代去噪
- Scheduler:控制噪声调度策略(如DDIM、PNDM等)
- 生成流程
(1)文本编码阶段
- 输入文本通过CLIP模型转换为语义向量(Text Embeddings)
- 文本信息被映射到与图像特征对齐的跨模态语义空间
(2)潜在空间初始化
- 生成512×512图像时,先创建64×64的随机噪声张量(latent tensor)
- 该张量存在于VAE的潜在空间,存储维度为4x64x64(通道x高x宽)
(3)迭代去噪过程
- 通过1-50步的迭代(具体步数可调)逐步去除噪声:
pythonCopy Code
# 伪代码示例
for t in reversed(range(num_steps)):
predicted_noise = UNet(latent, t, text_embeddings)
latent = scheduler.step(latent, predicted_noise, t)
- UNet在每个时间步预测噪声并更新潜在表示
- Classifier-Free Guidance机制增强文本控制(通过guidance_scale参数调节)
(4)潜在空间解码
- 最终潜在张量通过VAE解码器转换为768×768或512×512像素图像
- VAE解码器通过反卷积网络重建细节
- 关键技术特性
- 语义对齐:CLIP模型实现跨模态语义理解
- 计算优化:在1/64压缩率的潜在空间操作,显存需求降低约16倍
- 注意力机制:UNet中的Cross-Attention层实现文本-图像特征对齐
1、文本编码器
- CLIP 文本编码器作用:Stable Diffusion 使用 CLIP(对比语言 – 图像预训练模型)的文本编码器部分。当用户输入一段文本提示词,如 “一幅美丽的日落海景图”,CLIP 文本编码器会对这段文本进行处理。它通过学习大量的文本 – 图像对数据,能够理解文本中的语义信息,并将文本转换为高维的特征向量。在这个过程中,文本中的每个词语、短语以及它们之间的语义关系都会被编码到这个向量中。例如,“日落”“海景” 等关键元素的语义都会在向量中有所体现,使得这个向量包含了生成符合文本描述图像所需的语义指导信息。
- 向量输出影响:输出的文本特征向量会作为后续生成过程的重要输入,引导整个图像生成流程朝着符合文本描述的方向进行。它就像是给图像生成过程提供了一个 “蓝图”,模型会依据这个向量所携带的语义信息来生成相应的图像内容。
2、UNet
- 降噪自编码器结构:UNet 是一种基于卷积神经网络的降噪自编码器结构。在 Stable Diffusion 中,它的主要任务是根据文本编码器输出的文本特征向量以及一个初始的随机噪声图像,逐步对噪声进行去噪处理,从而生成目标图像。UNet 具有独特的 U 型结构,包含下采样路径和上采样路径。下采样路径通过一系列卷积操作,逐步降低图像的分辨率,同时提取图像的特征信息;上采样路径则通过反卷积等操作,逐步恢复图像的分辨率,并将下采样过程中提取的特征信息进行融合,以生成最终的图像。
- 噪声到图像生成过程:在生成过程开始时,UNet 会获取一个初始的随机噪声图像,这个噪声图像可以看作是一个完全混乱、没有任何语义信息的图像。然后,UNet 在文本特征向量的指导下,通过多次迭代的去噪操作,逐渐调整噪声图像的像素值,使得图像中的像素分布逐渐符合文本描述的内容。例如,在生成 “日落海景图” 时,UNet 会根据文本特征向量中关于日落的颜色、海景的形态等信息,逐步将噪声图像中的像素调整为橙红色的天空、蓝色的海洋以及海浪等形状和颜色,从而生成一幅初步的图像。
3、变分自编码器(VAE)
- 编码与解码原理:VAE 在 Stable Diffusion 中起到了图像压缩与重建的作用。在训练阶段,VAE 学习将高分辨率的真实图像压缩到低维的潜空间,同时也学习如何从潜空间中的向量重建出高分辨率图像。编码器部分会将输入的图像转换为潜空间中的一个向量表示,这个向量包含了图像的关键特征信息,但数据量大幅减少,降低了后续处理的计算复杂度。解码器则执行相反的操作,从潜空间向量中重建出高分辨率图像。在文生图过程中,UNet 生成的初步图像会先经过 VAE 的编码器转换到潜空间,然后再通过解码器将潜空间向量解码为最终的高分辨率图像。
- 对生成图像质量的影响:VAE 能够对 UNet 生成的图像进行优化,使得生成的图像在细节和整体结构上更加接近真实图像。它通过学习图像的统计特征,能够在重建图像时补充一些细节信息,并且使图像的颜色、纹理等方面更加自然和逼真。例如,在生成的 “日落海景图” 中,VAE 可以让天空的颜色过渡更加自然,海浪的纹理更加细腻,从而提高生成图像的质量。
4、训练与推理过程
- 训练阶段:在训练 Stable Diffusion 模型时,会使用大量的文本 – 图像对数据。模型通过不断调整文本编码器、UNet 和 VAE 的参数,使得模型能够准确地将文本描述转换为对应的图像。在这个过程中,会使用一些损失函数来衡量生成图像与真实图像之间的差异,以及文本特征向量与图像特征向量之间的一致性,然后通过反向传播算法不断优化模型参数,以最小化这些损失函数。
- 推理阶段:当用户输入文本提示词进行文生图时,模型进入推理阶段。文本编码器首先将文本转换为特征向量,然后 UNet 根据这个向量和初始噪声图像进行去噪生成初步图像,最后 VAE 对初步图像进行处理得到最终的生成图像。整个过程是一个快速的、基于已训练好的模型参数进行计算的过程,从而能够在较短时间内生成符合用户文本描述的图像。














还没有评论呢,快来抢沙发~